开放分布式追踪OpenTracing入门与Jaeger实现 数据处理与存储支持服务解析
引言:分布式系统中的追踪挑战
在现代微服务架构中,一个用户请求往往需要经过多个服务的协作处理。当系统出现性能瓶颈或错误时,传统的单体应用调试方法已不再适用。开放分布式追踪(OpenTracing)应运而生,为解决分布式系统的可观测性问题提供了标准化方案。
一、OpenTracing核心概念解析
1.1 什么是OpenTracing?
OpenTracing是一个中立的分布式追踪API规范,它定义了追踪数据采集的通用接口,使开发者能够以统一的方式在不同的追踪系统中实现分布式追踪。
1.2 核心组件
- Trace(追踪):代表一个完整的事务流程,由多个Span组成
- Span(跨度):代表一个工作单元,包含操作名称、开始时间、持续时间等
- Span Context(跨度上下文):在服务间传递的追踪信息,包含Trace ID、Span ID等
- Tags(标签):用于记录Span的键值对元数据
- Logs(日志):记录特定时间点的事件
二、Jaeger架构与数据处理流程
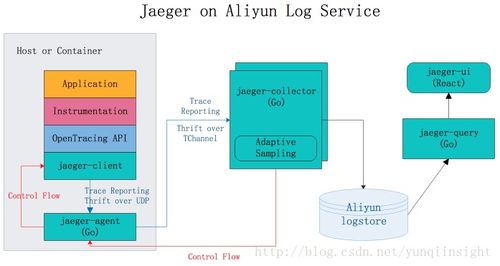
2.1 Jaeger整体架构
Jaeger是CNCF孵化的开源分布式追踪系统,完全兼容OpenTracing API,其架构包含以下核心组件:
- Jaeger Client:集成在应用程序中的SDK,负责生成追踪数据
- Jaeger Agent:部署在每个主机上的守护进程,接收Client数据并转发给Collector
- Jaeger Collector:接收Agent数据,进行验证、处理和存储
- Query Service:提供查询接口,从存储中检索追踪数据
- Jaeger UI:可视化界面,展示和分析追踪结果
2.2 数据处理流程详解
数据采集阶段
当应用程序处理请求时,Jaeger Client会:
- 创建Trace和Span
- 注入Span Context到请求头中
- 记录操作耗时、标签和日志
- 将Span数据异步发送到Jaeger Agent
数据聚合与处理
Jaeger Collector接收到数据后执行:
- 数据验证:检查Trace和Span格式的正确性
- 索引构建:为快速查询创建索引(如服务名、操作名、标签等)
- 数据转换:将Span数据转换为存储后端支持的格式
- 采样决策:根据配置的采样策略决定是否存储完整追踪数据
三、存储支持服务深度剖析
3.1 存储后端选项
Jaeger支持多种存储后端,各有适用场景:
Elasticsearch(推荐用于生产环境)
- 优势:
- 强大的全文搜索和聚合能力
- 良好的水平扩展性
- 丰富的查询语法
- 配置要点:
- 需要合理设置分片和副本数
- 建议使用时间索引模式(如jaeger-span-yyyy-mm-dd)
- 配置适当的索引生命周期策略
Cassandra
- 优势:
- 高写入吞吐量
- 优秀的可扩展性
- 灵活的数据模型
- 注意事项:
- 需要维护单独的集群
- 查询模式相对固定
内存存储(仅适用于测试)
- 重启后数据丢失
- 适用于POC和开发测试
3.2 数据存储优化策略
采样策略配置
合理的采样能平衡存储成本和数据完整性:
- 恒定采样:固定比例采样(如1%)
- 速率限制采样:每秒最多采样N个Trace
- 自适应采样:根据系统负载动态调整采样率
存储生命周期管理
- 索引轮转:定期创建新索引,避免单个索引过大
- 数据保留策略:
- 热数据:保留7天,支持快速查询
- 温数据:保留30天,查询性能稍低
- 冷数据:归档到对象存储,需要时再恢复
- 数据压缩:对历史数据进行压缩存储
3.3 高可用与扩展性设计
Collector集群化部署
- 多个Collector实例组成集群
- 负载均衡器分发Agent请求
- 共享存储确保数据一致性
存储层扩展方案
- Elasticsearch:增加数据节点提升容量和性能
- Cassandra:添加新节点实现线性扩展
- 使用读写分离架构减轻存储压力
四、实战:Jaeger数据处理与存储配置示例
4.1 Docker部署配置
`yaml
# docker-compose.yml
version: '3'
services:
jaeger-collector:
image: jaegertracing/jaeger-collector
environment:
- SPANSTORAGETYPE=elasticsearch
- ESSERVERURLS=http://elasticsearch:9200
- ESTAGSASFIELDSALL=true
elasticsearch:
image: docker.elastic.co/elasticsearch/elasticsearch:7.10.0
environment:
- discovery.type=single-node
- "ESJAVAOPTS=-Xms512m -Xmx512m"`
4.2 采样策略配置示例
{
"service_strategies": [
{
"service": "payment-service",
"type": "probabilistic",
"param": 0.5
},
{
"service": "order-service",
"type": "ratelimiting",
"param": 10
}
],
"default_strategy": {
"type": "probabilistic",
"param": 0.1
}
}五、监控与运维最佳实践
5.1 关键指标监控
- 采集性能:Spans/s、Traces/s
- 处理延迟:Collector处理时延
- 存储性能:ES/Cassandra读写延迟、磁盘使用率
- 采样效果:实际采样率与配置对比
5.2 故障排查指南
- 数据丢失排查:检查Agent-Collector连接、采样配置、存储可用性
- 查询性能优化:优化ES索引设置、添加适当的分片和副本
- 资源瓶颈识别:监控Collector CPU/内存使用,及时扩容
六、未来发展趋势
6.1 OpenTelemetry融合
OpenTelemetry是OpenTracing和OpenCensus的合并项目,提供统一的遥测数据采集标准。Jaeger已开始支持OpenTelemetry协议,未来将实现更平滑的过渡。
6.2 智能分析与预测
结合机器学习技术,实现:
- 异常检测:自动识别异常服务调用模式
- 根因分析:快速定位性能问题根源
- 容量预测:基于历史数据预测资源需求
##
分布式追踪已成为现代云原生应用不可或缺的可观测性工具。通过理解OpenTracing标准和Jaeger的实现机制,特别是数据处理和存储支持的原理,团队能够构建高效、可靠的追踪系统。合理的存储设计、采样策略和运维实践,将在保证系统可观测性的有效控制成本和复杂度。随着OpenTelemetry等新技术的发展,分布式追踪生态系统将更加完善,为复杂分布式系统的运维提供更强有力的支持。
掌握这些核心技术,不仅能够提升系统调试和性能优化的效率,更能为业务稳定性和用户体验提供坚实保障。
如若转载,请注明出处:http://www.wqlyp.com/product/31.html
更新时间:2026-06-01 09:51:29